
On HTML 5 Drag and Drop
By Francisco Tolmasky on
HTML 5 is shaping up to be quite an impressive step up from the capabilities web developers are currently constrained to. One of my favorite new features provided by the spec is support for native drag and drop. Cappuccino and many other JavaScript libraries have had drag and drop support for quite a while now, but with one important caveat: the drag operations were limited to within the browser window. This was not only visually displeasing, but prevented you from being able to share data in a user friendly way from one web app to another, or even to other desktop apps. HTML 5 aims to change all this by giving us access to the computer’s native drag system and clipboard. I took the last week to really familiarize myself with this API and its various implementations on current browsers so I could start adding support for it in Cappuccino. I feel that this gave me a pretty unique perspective on the current state of this feature which I’d like to share, mainly because I’ve had to make it work in a number of real (sometimes shipping) applications, as opposed to simplying creating small demos. The good news is that last night I was able to land my first commit which adds full HTML 5 drag and drop support for Safari and other WebKit-based browsers. Here is a short movie that shows this feature in action in our internal 280 Slides builds:
As you can see, this feature enables you to easily share data, whether it be images and shapes or full slides, from one presentation to another. What’s particularly cool about this is that you won’t have to change your existing code at all since Cappuccino simply detects when you are on a compliant browser and magically “upgrades” to native drag and drop. On older browsers, you will still get the old in-browser implementation. Ah, the beauty of abstraction.
This isn’t to say that working with this feature was all peaches and cream though. For starters, this feature is far from complete in any browser. I experienced a tremendous amount of bugs, crashes, and inconsistencies in all the browsers I tried. On the one hand, I got to play with a very exciting new toy, and on the other I was given a glimpse into the future of the bugs I would be dealing with for years to come (just when we thought the whole cross-browser thing was starting to become managable). This isn’t surprising of course, it is a very new addition and the spec isn’t even 100% complete yet. For this reason, I’ve decided to split this post up into two pieces. In the following I will be discussing what I believe to be actual and serious design flaws in the current API, as well as a few suggestions I have for how they might be remedied. I will also separately link to a page that has all the bugs and inconsistencies I discovered (as well as the associated tickets I filed on them), and workarounds when I could find them.
I believe the main “theme” of the problems I encountered was due to the fact that I am trying to build full-blown applications as opposed to dynamic web pages. This however is no excuse, as one of HTML 5′s supposed goals is to usher in an era of more web apps that are more competitive with desktop apps. This is precisely why Google is supporting it so heavily.
Lazy Data Loading
One of the key facilities of drag and drop is the ability to provide, and get, multiple representations of the same data. Different web pages, web apps, and desktop apps support different kinds of data, so it is up to your application to give them something they can work with. Take 280 Slides for example: When a user drags the slides out of slides navigator, he may be planning to drop it to any number of locations. If he is dragging it from one instance of 280 Slides to another, then we want to provide a serialized version of these slides so that they can be added to the other presentation. If however, he drags these slides into a program like Photoshop, then we would want to provide image data. If he were to drag them to his desktop, then perhaps we could provide a PDF version. He could even drag them to his text editor and expect the text contents of his slides to be pasted.
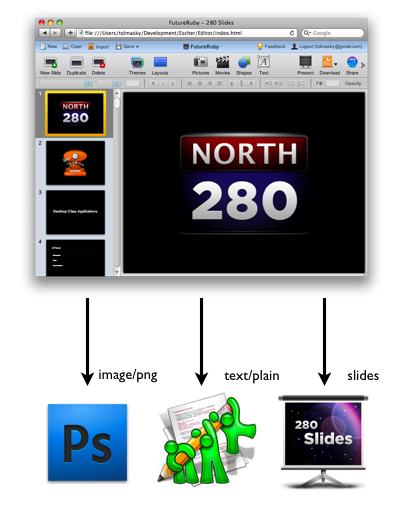
Multiple Data Types
The way you do this currently is with the setData function, which allows you to specify different types of data:
This is incredibly common on the desktop, and you’ve probably never noticed it precisely because it works so well: things seem to just do the right thing when you drag and drop them. However, an unfortunate side effect of this feature is that you end up doing a lot of extra unecessary work. The user only ever drops the item to one location, and so all the other formats you’ve created were wasted processing time. This is not a big deal for simple cases of drag and drop, but it becomes quite noticable in large applications like 280 Slides. In the example above, creating serialized and image representations of these slides can become quite slow depending on how many elements are in the individual slides and how many slides you are moving. Because of this you may experience a lag when you first drag the slides out. The worst part is, if all you intended to do was reposition the slides in the same presentation, then you didn’t need any of these formats!
This problem was solved in a very simple and intelligent way on the desktop a long time ago: simply delay supplying the actual data until the drop occurs. At the point of the drop, you actually know which of the 5 supplied types the user is interested in, so create it then. Not only does this save you from doing uncessary work, but generally users notice time spent processing after a drop a lot less (because there is no expected user feedback to stutter). I’ve thought a lot about a good way to allow the user to do this with the existing setData method , and I think it could be done by simply allowing developers to provide functions that could be called when the data is needed:
Perhaps a more backwards compatible alternative would be:
Although I don’t really think this is necessary since this API is so new. Either way, this allows us to use the existing setData method, while not actually needing to calculate the string value until getData is actually called by the drop target.
Initiating Drags Another major hurdle I encountered was in controling the way drags are actually started. Currently this is a delicate dance of preventDefaults and interactions between mousedown, mousemove, and dragstart, in combination with the draggable HTML attribute. The basic problem with this is that it leaves the decision to create a drag entirely to the the browser. Again, this is just fine for simple cases, but it really starts to break down when you are building full on applications in the browser. On the other hand, frameworks like Cocoa allow the developer to initiate the actual drag sequence. Lets look at why this is important with a simple example. It is quite common to want to start a drag event on the initial mouse down, instead of waiting for additional mouse move events. In these cases, it would be more confusing if the initial mouse down did nothing. This is currently impossible to achieve with the HTML 5 drag and drop APIs. In Cocoa, this would be quite simple, requiring the developer simply start the process in mouseDown: instead of mouseDragged:
This is just a simple example of course. More complex widgets provide even more cases where drag and drop in the browser really works against you. Take tables in Mac OS X, which provide different behaviors depending on what direction the users drags in:
As you can see, when a user drags upwards in a table on Mac OS X, the selection of the table changes (in other words, no drag takes place). On the other hand, if the user drags left, right, or diagonally in any way, then he is allowed to move these files. This is very intuitive experience when you use it, and is absolutely trivial to implement in Cocoa:
However, this is again basically impossible with the current HTML 5 API, as you can never be a part of the decision as to whether an object is dragged or not. Once you get the drag event, it’s too late. You can imagine that this would become even more cumbersome in applications like Bespin that revolve less around specific tags and more around content that is drawn to a canvas elements. When a user drag in Bespin, they have to decide between any number of actions. I think a good solution to this would be to simply allow the developer to manually kick off a dragging event loop from either a mousedown or mousemove callback. Something like this:
In both these cases, calling startDrag would result in no further mousemoves/mouseups being fired in this event loop, and instead would kick off the drag event loop with a “dragstart” event. A matching cancelDrag() could be provided as well. This would allow you to cancel a drag, but not any other specific behavior such as selection. Currently calling preventDefault cancels both drags and selection. This actually leads to a number of other confusing results. For example, if you place a textfield within a draggable element, it is essentially impossible for text selection to happen in that textfield, even if you set the textfield itself to not be draggable.
Drag Images
One of the nice parts about drag and drop is that you are allowed to set any arbitrary image or element as what is actually rendered during the drag process with the setDragImage method:
However, on Firefox it is required that this element already be visible. Now, I wasn’t sure whether to list this as simply a bug in Firefox or an actual design flaw, but I chose to list it as a flaw because the documentation at mozilla.org would seem to suggest that they may consider this to be “correct behavior”. Safari does not have this restriction, and in fact Firefox even seems to make an exception for canvas elements. Firefox seems particularly strict about this requirement too, as I tried positioning an element offscreen in a negative position, setting its visibility to hidden, setting the display to none, and even placing the element in an offscreen iframe, anything to prevent having to actually flash the element in some random portion of the screen before dragging it. It seems to me that this method exists for the purpose of showing something different, and thus it’s a bit unreasonable to expect it to already be not only in the document, but visible as well. My request here is simple: that it should simply work the way it does in Safari.
Conclusion
Drag and drop is an incredibly important part of the way we interact with computers, which is why it is so crucial that we get it right from the beginning. I really hope my concerns are heard and that we can come up with some good solutions to the initial problems I faced with this young API, so that we can avoid the windows of incompatibility that plagued the last updates to HTML. In the meanwhile, I’ve filed a bunch of bugs and documented my current experiences here.